Reddit is a goldmine of unfiltered opinions, market research, and trend signals. With over 50 million daily active users discussing everything from niche software tools to the latest investment opportunities, Reddit contains data that simply does not exist anywhere else on the internet.
But getting that data out of Reddit and into a usable format? That is where most people hit a wall.
If you have ever tried to copy discussion threads into a spreadsheet, you know the pain. You click on a post, copy the title, paste it into cell A1. Then you scroll down to grab the top comment, paste it into B1. Repeat this 200 times for a single subreddit, and you have lost an entire afternoon to what should be a simple data collection task.
In this guide, we will show you how to scrape Reddit data without writing a single line of code using Lection, an AI-native web scraping tool. By the end, you will know how to export subreddit posts, comments, upvotes, and more directly into Google Sheets or Excel.
Why Reddit Data Matters in 2025
Reddit is not just a social media platform; it is a real-time pulse on consumer sentiment. Here are some practical use cases where Reddit data provides unique value:
Market Research and Competitive Intelligence
Want to know what users really think about a SaaS product? Search for that product name on Reddit. You will find unfiltered complaints, feature requests, and comparisons that no marketing site will ever show you. One product manager we spoke with discovered three major feature gaps simply by scraping 500 posts from the r/productivity subreddit.
Content Ideas and Trend Spotting
Subreddits like r/Entrepreneur and r/startups are filled with questions people are actively asking. These questions translate directly into blog topics, YouTube video ideas, or product opportunities. Scraping the top 100 posts from a subreddit gives you a library of validated content ideas.
Academic Research and Sentiment Analysis
Researchers increasingly turn to Reddit for social science studies. The platform's threaded discussions provide rich qualitative data for sentiment analysis, linguistic studies, and behavioral research. A 2024 study on mental health discourse analyzed over 10,000 Reddit posts to identify patterns in how users discuss anxiety.
The Problem with Getting Reddit Data
If Reddit data is so valuable, why is it so hard to collect?
Manual Copy-Paste is a Time Sink
The math is brutal. Copying a single Reddit post with its top 5 comments takes about 90 seconds if you are fast. To build a dataset of 200 posts, you are looking at 5+ hours of mind-numbing work. Your brain was not designed for this kind of repetitive labor.
Reddit's API Restrictions Have Tightened
In 2023, Reddit made headlines by implementing significant API pricing changes. What was once free programmatic access now costs $0.24 per 1,000 API calls. Popular third-party apps like Apollo, Sync, and Reddit Is Fun shut down because the costs became unsustainable.
For individual researchers or small teams, building a custom API integration is no longer economically viable. You would need to navigate rate limits, handle authentication tokens, and pay for every request.
Traditional Scrapers Break Constantly
Reddit frequently updates its frontend code. If you have tried using Python scripts with libraries like BeautifulSoup, you have probably experienced the frustration of waking up to a broken scraper because Reddit changed a div class name overnight. Maintaining these scripts becomes a part-time job.
How Lection Solves the Reddit Scraping Problem
Lection is an AI-native Chrome extension that transforms how you extract web data. Instead of relying on brittle CSS selectors or expensive API calls, Lection uses AI agents to visually understand the page structure.
Here is why Lection works exceptionally well for Reddit:
- No Code Required: Point and click to select the data you want. No Python, no API keys.
- AI-Powered Adaptation: When Reddit changes its layout, Lection's AI automatically adjusts. No script maintenance required.
- Browser-Native: Lection runs right where you work. No context switching to external software.
- Cloud Scraping: Schedule your scrapes to run automatically, even when your laptop is closed.
Step-by-Step: Exporting Reddit Data to Google Sheets
Let us walk through a real example. Suppose you want to extract the top 100 posts from r/entrepreneur to analyze what topics are trending for startup founders.
Step 1: Install the Lection Chrome Extension
Head to the Chrome Web Store and install Lection. Pin it to your browser toolbar for easy access.
The installation takes seconds, and you now have a powerful data extraction agent living in your browser.
Step 2: Navigate to Your Target Subreddit
Open Reddit and navigate to the subreddit you want to scrape. For this example, go to reddit.com/r/entrepreneur.
You can sort by "Top" and select a time range (e.g., "Top of this month") to focus on the most engaging content.
Step 3: Activate the Lection Agent
Click the Lection icon in your browser toolbar. The sidebar will open, and Lection's AI will immediately start analyzing the page structure.
Because Reddit displays posts in a list format, Lection will automatically detect the repeating pattern. You will see it highlight the individual posts and suggest fields for extraction.
Step 4: Select Your Data Fields
Lection will likely auto-detect common fields like:
- Post Title
- Author Username
- Upvote Count
- Comment Count
- Post URL
- Time Posted
If you need additional fields, such as the flair tag or the first few lines of the post body, simply click on that element. Lection learns from your selection and applies the logic across all other posts.
Step 5: Enable Pagination for More Data
A single Reddit page shows around 25 posts. If you want the top 100, you need to handle pagination.
Toggle on the "Pagination" option in the Lection sidebar. The agent will automatically find the "Next" or infinite scroll mechanism and extract data from multiple pages, stacking everything into a single clean table.
[!TIP] Respect the Platform: Lection includes smart delays between page loads to mimic natural browsing behavior. This protects your account and keeps the scraping process sustainable.
Step 6: Extract Comment Data (Advanced)
Want to go deeper than just post titles? Lection supports "Deep Link Trawling." This feature allows the agent to click into each individual post and extract the comments.
For each post, you can capture:
- Top comment text
- Comment author
- Comment upvotes
- Threaded replies
This is invaluable for sentiment analysis or understanding the full context of a discussion.
Step 7: Export to Google Sheets or Excel
Once Lection finishes gathering the data, click Export. You have several options:
- How to get Reddit data into Google Sheets: Select the "Google Sheets" integration. Authenticate with your Google account once, pick a spreadsheet, and your data streams directly into the columns.
- Export Reddit data to Excel without coding: Click "Download as CSV" or "Excel" for a local file ready for pivot tables and analysis.
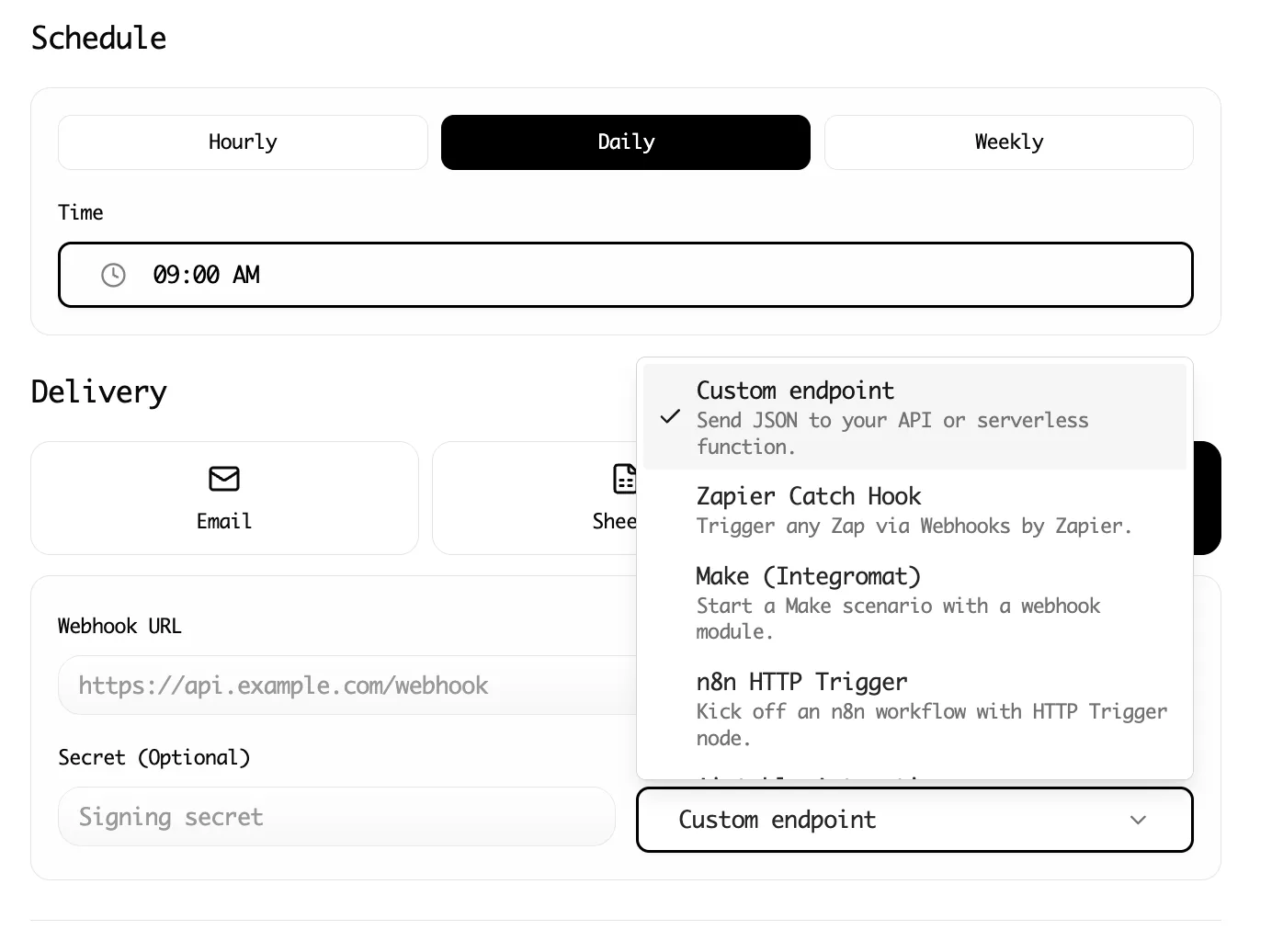
Pro Tip: Schedule Recurring Reddit Scrapes
Reddit trends move fast. What is on the front page of r/technology today will be buried in 48 hours.
With Lection's Cloud Scraping, you can schedule your scrapes to run automatically. Set it to extract the top posts from your target subreddits every Monday morning. When you start your week, a fresh dataset is waiting in your Google Sheet, without you lifting a finger.
This is particularly powerful for:
- Competitor Monitoring: Track mentions of your brand or competitors across relevant subreddits.
- Trend Tracking: Get weekly updates on emerging topics before they hit mainstream news.
- Content Calendars: Build a library of validated post ideas based on what Reddit users are actively discussing.
Common Pitfalls and How to Fix Them
Even with the best tools, scraping Reddit can present some challenges. Here is how to handle them:
"I'm Only Getting Old Reddit Data"
If you navigate to old.reddit.com, the layout is different from the modern Reddit redesign. Lection can scrape both, but make sure you are consistent. If you start on new Reddit, stay on new Reddit. The AI adapts to whichever layout you are using.
"Some Posts Are Missing Data"
Reddit uses lazy loading for some elements. If upvote counts or certain fields appear blank, try scrolling down the page before activating Lection. This ensures all elements are rendered in the DOM.
"I Hit a Rate Limit"
If you are running large scrapes (1,000+ posts), Reddit may temporarily throttle requests. Lection's Cloud Scraping handles this by using distributed infrastructure and smart delays. For manual browser scraping, take breaks between batches.
"Comments Are Collapsed"
Reddit collapses long comment threads by default. To extract all comments, you may need to click "load more comments" or use Lection's interactive automation features to expand threads before extraction.
Why Lection is the Best Choice for Reddit Data
There are other Reddit scraping options, but most fall short for non-technical users:
| Approach | The Problem |
|---|---|
| Python + PRAW | Requires coding skills and API costs $0.24/1,000 calls |
| Octoparse | Steep learning curve with desktop software |
| Manual Copy-Paste | Takes hours and leads to errors |
| Outsourcing to VAs | Quality varies and still time-consuming |
Lection offers a different path: AI-native scraping that adapts to Reddit's layout, runs in your browser, and requires zero code. It is the fastest way to go from "I need this data" to "I have this data in a spreadsheet."
Conclusion: Stop Copying, Start Analyzing
Your value is not in how fast you can copy-paste Reddit threads. It is in the insights you extract from the conversations happening on the platform.
By automating Reddit data extraction with Lection, you reclaim hours of your week. You can monitor brand mentions, discover content gaps, analyze competitor sentiment, and identify trends before they go viral.
Ready to turn Reddit into your own personal research database?
Install Lection for free today and export your first Reddit dataset in minutes.